La struttura della membrana determina una permeabilità selettiva
TOPICS
Definizione

La trascrizione rappresenta il primo stadio dell’espressione genica, cioè il passaggio con cui le informazioni codificate nei geni vengono lette e convertite in molecole di RNA. Un singolo gene può essere copiato ripetutamente, generando numerose molecole di RNA tra loro identiche. Nei geni codificanti per proteine, l’RNA agisce per lo più come intermediario informazionale e ciascun trascritto può essere tradotto più volte, determinando un’efficiente amplificazione del segnale proteico. La cellula modula in modo indipendente la velocità di trascrizione dei singoli geni e la frequenza di traduzione dei relativi RNA, così da ottenere concentrazioni molto diverse di proteine distinte (Figura 03.05-01). Oltre agli RNA messaggeri, esistono ampie classi di RNA non codificanti con funzioni strutturali, regolative e catalitiche, che concorrono alla gestione integrata dell’espressione genica.
Image Gallery
Per attivare uno dei numerosi geni presenti nel genoma, la cellula ne copia un tratto di sequenza in RNA. Il termine “trascrizione” riflette il fatto che il linguaggio chimico resta quello dei nucleotidi, pur cambiando la natura del polimero. Come il DNA, anche l’RNA è una catena lineare di nucleotidi uniti da legami fosfodiesterici; tuttavia si distinguono differenze chimiche rilevanti:
- i nucleotidi dell’RNA sono ribonucleotidi e contengono ribosio, mentre quelli del DNA contengono desossiribosio;
- l’RNA utilizza uracile (U) al posto della timina (T) tipica del DNA, pur condividendo adenina (A), guanina (G) e citosina (C) (Figura 03.05-02).
Poiché U si appaia con A tramite legami a idrogeno in modo analogo a T (Figura 03.05-03), valgono le stesse regole di complementarità già descritte per il DNA. Le due macromolecole differiscono però per l’architettura complessiva: il DNA è stabilmente organizzato in una doppia elica, mentre l’RNA è in genere a singolo filamento. Questa caratteristica consente all’RNA di ripiegarsi in strutture secondarie e terziarie definite, guidate da appaiamenti intramolecolari e interazioni non canoniche, con importanti conseguenze funzionali (Figura 03.05-04). Tale plasticità conformazionale spiega la varietà di funzioni dell’RNA, che includono ruoli catalitici (ad esempio negli RNA ribosomiali che contribuiscono all’attività peptidil–transferasica del ribosoma), ruoli strutturali (rRNA, tRNA), e di regolazione genica (snRNA, snoRNA, miRNA, lncRNA). Il DNA, per contro, è specializzato nell’immagazzinamento stabile dell’informazione genetica.
Image Gallery

Image Gallery
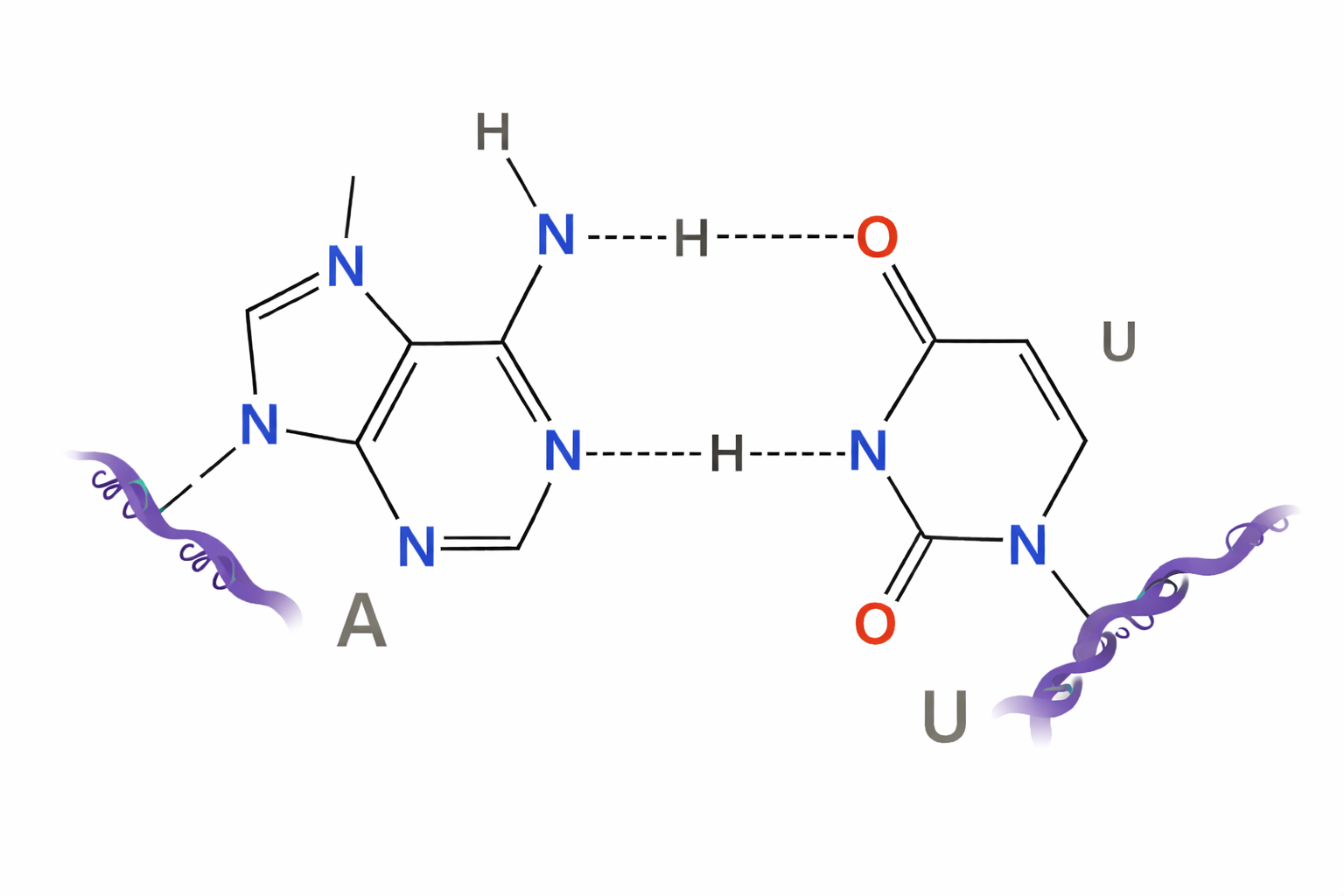
Image Gallery
Tutte le specie di RNA cellulari derivano da un meccanismo comune: la trascrizione. Il processo ha inizio con l’apertura locale della doppia elica del DNA, che espone brevi regioni di basi su entrambi i filamenti (bolla trascrizionale). Uno dei due filamenti funge da stampo e dirige l’incorporazione sequenziale dei ribonucleotidi, i quali si appaiano in modo complementare alle basi del filamento stampo. Quando l’appaiamento è corretto, l’RNA polimerasi catalizza la formazione del legame fosfodiesterico, estendendo la catena nascente di un nucleotide alla volta; la sequenza del trascritto risulta complementare a quella del filamento stampo (Figura 03.05-05). Convenzionalmente, il filamento di DNA non copiato è detto “codificante” perché la sequenza dell’mRNA ad esso corrisponde (eccetto la sostituzione U/T), mentre il filamento copiato è detto “stampo” o “non codificante”.
A differenza della replicazione, durante la trascrizione il filamento di RNA si distacca rapidamente dallo stampo appena sintetizzato. L’elica di DNA si richiude alle spalle dell’enzima, per cui il prodotto è un singolo filamento di RNA complementare a uno solo dei due filamenti di DNA. Inoltre, i trascritti sono notevolmente più corti delle molecole cromosomiche: un cromosoma umano può contenere centinaia di milioni di coppie di nucleotidi, mentre gli RNA maturi raramente superano poche migliaia di nucleotidi e molti sono più brevi.
Come le DNA polimerasi, le RNA polimerasi catalizzano la formazione di legami fosfodiesterici che uniscono l’ossatura zucchero–fosfato del polimero (Figura 03.05-02). L’elongazione procede in direzione \(5' \rightarrow 3'\) (Figura 03.05-06), con consumo di ribonucleosidi trifosfato (ATP, CTP, GTP, UTP). L’energia liberata dall’idrolisi del gruppo trifosfato, con rilascio di pirofosfato e sua successiva scissione, rende termodinamicamente favorevole la polimerizzazione.
Poiché il trascritto si separa dallo stampo man mano che viene prodotto, più molecole di RNA polimerasi possono impegnare lo stesso gene quasi simultaneamente; nuove inizi possono avvenire prima che l’elongazione precedente sia completata (Figura 03.05-07). Per un gene di circa 2 000 nucleotidi, un’RNA polimerasi che avanza a ~35 nucleotidi/s completa il trascritto in ~57 s; in condizioni permissive, decine di polimerasi distribuite lungo quel tratto possono generare diverse centinaia di trascritti all’ora, sebbene per molti geni fisiologici i tassi siano decisamente inferiori.
Nonostante la somiglianza della reazione chimica, le RNA polimerasi differiscono dalle DNA polimerasi in aspetti chiave: utilizzano ribonucleotidi invece di desossiribonucleotidi e non richiedono un innesco per avviare la sintesi. Inoltre, l’accuratezza è inferiore: la frequenza di errore è nell’ordine di un evento ogni \(10^4\) nucleotidi incorporati, mentre le DNA polimerasi, grazie a un’efficiente correzione di bozze, raggiungono valori intorno a \(10^7\) o meglio. Alcune RNA polimerasi possono effettuare un limitato “backtracking” con rimozione del nucleotide erroneo, ma l’assenza di un archivio permanente dell’informazione nell’RNA rende tollerabile una fedeltà più bassa. La diversità delle RNA polimerasi riflette anche l’organizzazione cellulare: nei procarioti è presente una singola RNA polimerasi con fattore sigma per il riconoscimento del promotore, mentre negli eucarioti coesistono almeno tre enzimi principali (I, II, III) con specificità di trascritti differenti e necessità di fattori generali di trascrizione per l’avvio.
L’individuazione dei geni da trascrivere dipende da sequenze di DNA caratteristiche, come promotori che dirigono l’inizio e segnali di terminazione che arrestano l’enzima; la loro interazione con l’RNA polimerasi e i fattori accessori coordina l’efficienza di inizio, l’accuratezza e la produttività della trascrizione, e costituisce un nodo cruciale della regolazione dell’espressione genica.
Image Gallery
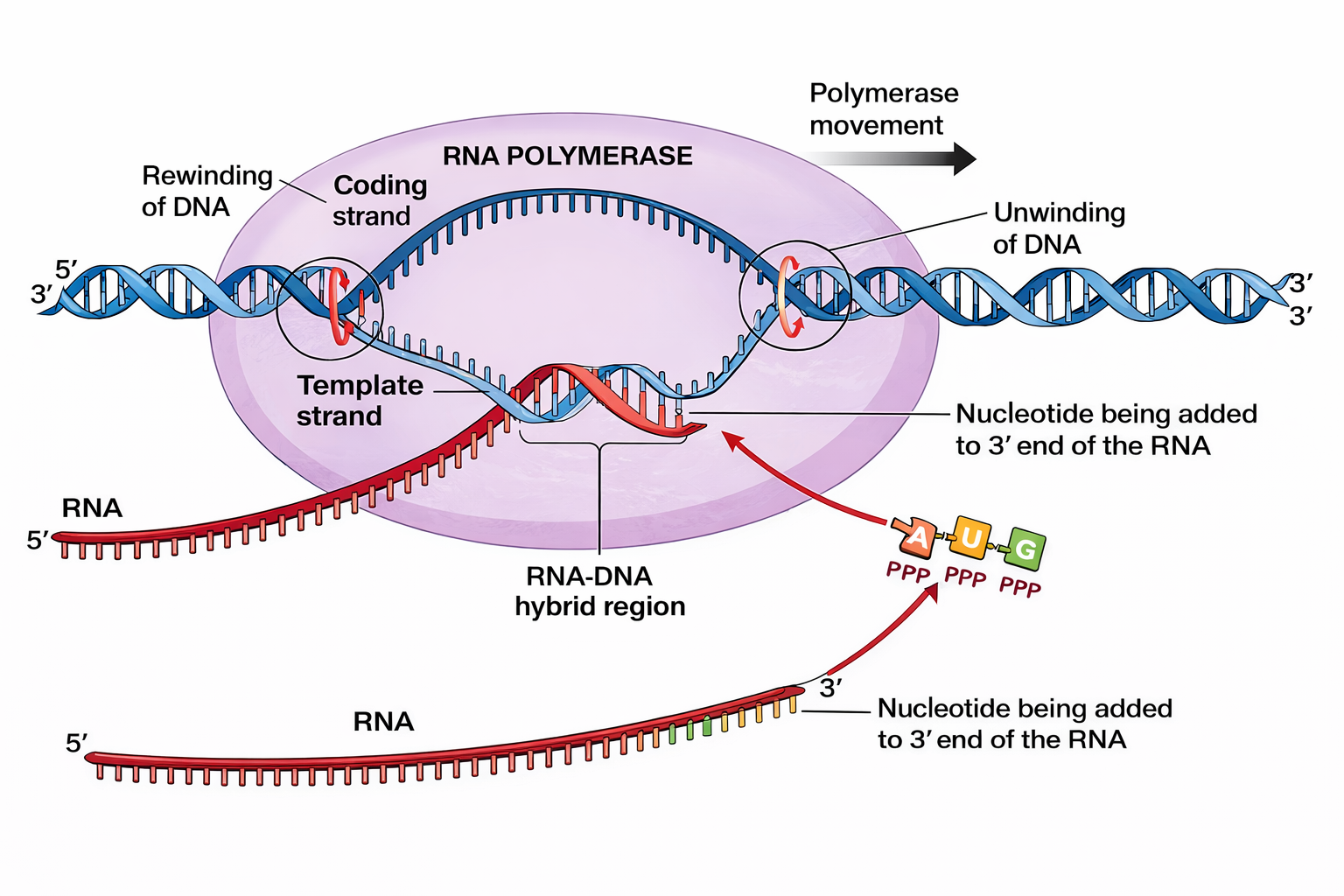
Image Gallery
Image Gallery

Image Gallery

Una porzione consistente dei geni contenuti nel DNA codifica per sequenze amminoacidiche che verranno tradotte in proteine. Gli RNA trascritti da questi loci, che fungono da intermedi informazionali tra DNA e apparato di sintesi proteica, sono noti come RNA messaggeri (mRNA). Negli eucarioti, un mRNA è in genere monocistronico, cioè deriva dalla trascrizione di un singolo gene e specifica una sola proteina; nei procarioti, al contrario, non è raro che un mRNA sia policistronico, poiché costituisce il trascritto di più geni adiacenti organizzati in operoni, consentendo la produzione coordinata di proteine funzionalmente collegate.
In altri casi, il prodotto finale dell’espressione genica non è una proteina, bensì l’RNA stesso, che agisce come molecola effettore. Questi RNA non codificanti possiedono funzioni regolative, strutturali o catalitiche, e sono indispensabili per la traduzione dell’informazione genetica e per il controllo fine dell’espressione genica. Tra i principali:
- gli RNA ribosomiali (rRNA), che costituiscono l’impalcatura strutturale e il nucleo catalitico dei ribosomi, sede della traduzione degli mRNA in catene polipeptidiche;
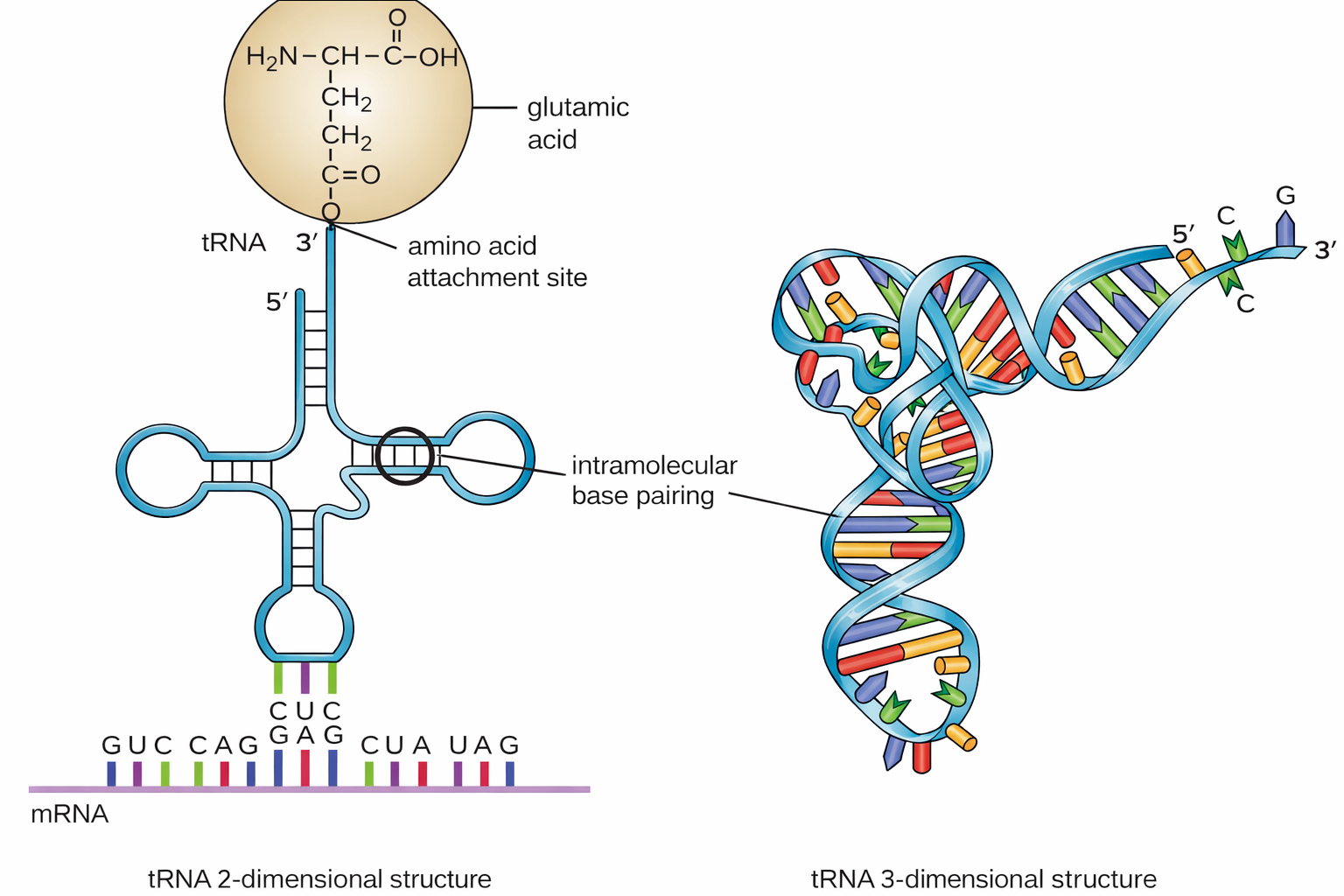
- gli RNA transfer (tRNA), che operano come adattatori molecolari: riconoscono i codoni dell’mRNA e veicolano gli amminoacidi corrispondenti al sito peptidil-transferasico del ribosoma, garantendo l’accurato inserimento residuo per residuo;
- i microRNA (miRNA), piccoli RNA regolativi eucariotici che modulano l’espressione genica post-trascrizionale, in genere riducendo la stabilità degli mRNA o inibendone la traduzione.
Oltre a queste classi, nelle cellule si repertoriano ulteriori RNA non codificanti con ruoli definiti: gli snRNA e snoRNA, coinvolti rispettivamente nello splicing e nella maturazione/modifica dell’rRNA; gli siRNA e i piRNA, che mediano silenziamento genico e difesa genomica; i lncRNA, che partecipano a processi di regolazione trascrizionale ed epigenetica. I principali tipi di RNA sono riassunti nella (Tabella 03.05-01).
Con espressione genica si intende, in senso ampio, l’insieme dei passaggi mediante i quali l’informazione codificata nel DNA viene convertita in un prodotto funzionale che esercita un effetto fenotipico sulla cellula o sull’organismo. Se il prodotto è una proteina, il processo include trascrizione e traduzione; se il prodotto è un RNA funzionale, la via si arresta alla trascrizione e all’eventuale maturazione dell’RNA stesso.
Tipi di RNA nelle cellule
| Tipo di RNA | Funzione |
|---|---|
| RNA messaggeri (mRNA) | Portano l’informazione genetica necessaria per la sintesi delle proteine |
| RNA ribosomiali (rRNA) | Costituiscono la struttura principale dei ribosomi e catalizzano la formazione dei legami peptidici |
| microRNA (miRNA) | Regolano l’espressione genica modulando la traduzione degli mRNA |
| RNA transfer (tRNA) | Agiscono da adattatori tra codoni dell’mRNA e amminoacidi durante la traduzione |
| Altri RNA non codificanti | Coinvolti nello splicing, nel controllo dei telomeri, nella regolazione genica e in numerosi altri processi cellulari |
| Tabella che riassume le principali classi di RNA presenti nelle cellule, evidenziandone le funzioni specifiche nella trasmissione dell’informazione genetica, nella sintesi proteica, nella struttura e nel funzionamento dei ribosomi e nella regolazione dell’espressione genica e della stabilità del genoma. | |
La fase di inizio della trascrizione rappresenta un nodo regolativo primario: è in questo punto che la cellula decide quali geni attivare, in quali quantità e in quali condizioni. Per avviare la sintesi di un trascritto, l’RNA polimerasi deve individuare l’incipit corretto di un gene e stabilire un’interazione ad alta affinità con il DNA in quella regione. Le modalità con cui questo riconoscimento avviene differiscono tra procarioti ed eucarioti, motivo per cui è utile considerare prima il sistema batterico, più lineare nella sua organizzazione.
Quando l’RNA polimerasi batterica intercetta la doppia elica, può aderire debolmente e “scorrere” lungo il DNA fino a incontrare un promotore, ossia una sequenza specifica di nucleotidi che segnala il punto di avvio della trascrizione. Una volta legata il promotore con alta specificità, l’enzima promuove l’apertura locale della doppia elica, generando una “bolla” di trascrizione che espone i nucleotidi di entrambi i filamenti. Il filamento stampo viene selezionato come matrice per l’appaiamento dei ribonucleotidi in ingresso e l’RNA polimerasi catalizza la formazione dei primi legami fosfodiesterici, dando inizio all’allungamento del trascritto (Figura 03.05-08).
La progressione procede in direzione \(5'\to 3'\), con incorporazione sequenziale dei nucleotidi complementari. L’enzima continua fino a raggiungere un segnale di terminazione, o terminatore, una sequenza del DNA che determina l’arresto della trascrizione e il rilascio del neo-RNA e della matrice. È importante notare che il segnale di terminazione è contenuto nella regione trascritta e si riflette nella porzione 3′ del trascritto; nei batteri, i terminatori possono essere intrinseci (rho-indipendenti), basati sulla formazione di forcelle a stem–loop nel trascritto seguite da una serie di uracili, o dipendenti da fattori proteici (Rho), che promuovono il distacco dell’enzima. Le sequenze consenso di un promotore batterico tipico e un esempio di segnale di terminazione (talvolta indicato impropriamente come “codone di stop” in ambito didattico) (Figura 03.05-09) sono riportati nelle figure corrispondenti.
Affinché un tratto di DNA sia trascritto, deve essere preceduto da un promotore funzionale; la forza del promotore, determinata dalla somiglianza alle sequenze consenso e dal contesto cromatinico/strutturale, contribuisce al livello di espressione del gene. Nella RNA polimerasi batterica (Figura 03.05-08), il riconoscimento del promotore è mediato essenzialmente dalla subunità σ (fattore sigma), che interagisce con motivi conservati localizzati a circa −35 e −10 nucleotidi a monte del sito di inizio (+1). Le basi esposte nel solco maggiore del DNA presentano pattern chimici distintivi che permettono al fattore σ di “leggere” la sequenza senza separare i filamenti. Durante l’apertura della bolla trascrizionale, σ stabilizza temporaneamente l’elica srotolata, facilitando la formazione dei primi legami fosfodiesterici e la transizione dall’iniziazione all’allungamento.
Un problema concettuale cruciale è la scelta del filamento di DNA da utilizzare come stampo. I due filamenti contengono informazioni differenti e, se trascritti, condurrebbero a RNA diversi. La soluzione risiede nella polarità intrinseca del promotore, che impone all’RNA polimerasi un orientamento univoco sul DNA. Poiché l’enzima catalizza la sintesi soltanto nella direzione \(5'\to 3'\), una volta posizionata correttamente, la polimerasi impiega come matrice il filamento orientato \(3'\to 5'\). Questo vincolo è determinato dalla disposizione asimmetrica degli elementi del promotore a monte del +1 (Figura 03.05-09).
La direzione di trascrizione non è fissa a livello cromosomico: su uno stesso cromosoma, diversi geni possono essere trascritti in direzioni opposte, a seconda dell’orientamento del rispettivo promotore. In genere, ciascun gene dispone di un solo promotore principale, il cui orientamento definisce quale filamento fungerà da stampo e in quale direzione procederà l’enzima per quel gene (Figura 03.05-10). Arrangiamenti con promotori divergenti o convergenti possono tuttavia verificarsi, soprattutto in regioni regolative complesse.
Nei sistemi eucariotici, il principio generale è conservato, ma l’architettura molecolare è più articolata: coesistono tre RNA polimerasi nucleari principali (I, II e III), ciascuna specializzata per specifiche categorie di geni; il riconoscimento del promotore da parte della RNA polimerasi II richiede fattori generali della trascrizione (per esempio il complesso TFIID, che include la proteina legante la TATA box, TBP), e l’accesso al DNA è modulato dalla cromatina e dalle modificazioni degli istoni. Pur non entrando nel dettaglio eucariotico, questa complessità riflette la necessità di un controllo multilivello nell’iniziazione e nella terminazione della trascrizione.
In sintesi, l’avvio e la conclusione della trascrizione sono determinati da segnali codificati nella sequenza del DNA e interpretati dall’RNA polimerasi e dai suoi cofattori. La presenza, l’orientamento e la qualità del promotore stabiliscono dove e in che direzione avviare la trascrizione, mentre i terminatori determinano il punto di arresto e il rilascio del trascritto, garantendo la produzione di RNA con estremità definite e competenti per le successive fasi di maturazione e funzione.
Image Gallery
Image Gallery
Image Gallery
Image Gallery
Image Gallery
Molti principi fondamentali della trascrizione sono condivisi tra procarioti ed eucarioti; tuttavia, le modalità con cui negli eucarioti ha inizio la sintesi di RNA divergono in aspetti chiave di natura strutturale e regolativa. Tali differenze impattano sia l’architettura del complesso di inizio, sia l’integrazione dei segnali regolatori sul DNA cromatinizzato:
- pluralità di RNA polimerasi e specializzazione funzionale: nei batteri un’unica RNA polimerasi gestisce la trascrizione, mentre negli eucarioti operano tre enzimi distinti, RNA polimerasi I, II e III, ciascuno dedicato a classi specifiche di geni; la polimerasi I sintetizza il precursore dell’rRNA maggiore, la polimerasi III produce 5S rRNA, tRNA e alcuni RNA non codificanti aggiuntivi, e la polimerasi II trascrive la maggior parte dei geni, inclusi tutti quelli codificanti proteine (Tabella 03.05-02);
- dipendenza da complessi proteici ausiliari: a differenza della RNA polimerasi batterica che, coadiuvata da sigma, può iniziare la trascrizione, le RNA polimerasi eucariotiche necessitano di molteplici cofattori; i più determinanti sono i fattori generali di trascrizione, che si assemblano sul promotore per reclutare e posizionare l’enzima;
- regolazione multilivello e controllo a lunga distanza: nei procarioti i geni sono spesso contigui e separati da brevi tratti intergenici; negli eucarioti, invece, i geni sono distanziati da ampie regioni non codificanti (anche 100 000 coppie di nucleotidi) e sono soggetti a reti di elementi regolatori (enhancer, silencer, insulator) anche molto lontani, con integrazione spaziale mediata dall’organizzazione 3D del genoma;
- influenza della cromatina: il DNA eucariotico è avvolto in nucleosomi e ulteriormente compattato in strutture superiori, imponendo barriere fisiche e regolative che devono essere rimodellate per consentire l’accesso dell’apparato trascrizionale.
Sulla base di queste premesse, l’attenzione si concentra sui fattori generali di trascrizione e su come facilitano l’avvio catalizzato dalla RNA polimerasi II.
Funzioni delle RNA polimerasi negli eucarioti
| Tipo di polimerasi | Geni trascritti |
|---|---|
| RNA polimerasi I | Trascrive la maggior parte dei geni dell’rRNA ribosomale |
| RNA polimerasi II | Trascrive geni codificanti proteine, miRNA e diversi RNA non codificanti (es. snRNA) |
| RNA polimerasi III | Trascrive geni per tRNA, rRNA 5S e numerosi piccoli RNA |
| Tabella che riassume le tre RNA polimerasi delle cellule eucariotiche, indicando per ciascuna le specifiche classi di RNA sintetizzate e il loro ruolo nel controllo dell’espressione genica e nella produzione delle molecole essenziali per la vita cellulare. | |
La RNA polimerasi II purificata non è in grado di avviare autonomamente la sintesi di RNA; esperimenti biochimici hanno quindi condotto all’identificazione e purificazione dei fattori generali di trascrizione. Questi complessi proteici riconoscono il promotore, orientano la polimerasi, promuovono l’apertura della doppia elica e stabiliscono il sito d’inizio, svolgendo negli eucarioti un ruolo concettualmente analogo a quello del fattore sigma nei batteri.
Come illustrato in (Figura 03.05-11), l’assemblaggio sul promotore culmina nella formazione del complesso di pre-inizio (PIC). Nella maggioranza dei promotori della polimerasi II, un passaggio iniziale cruciale è il legame del fattore TFIID a specifici elementi del promotore. TFIID contiene la TATA-binding protein (TBP), che riconosce la TATA box, una breve sequenza ricca in A e T posta di norma circa 30 nucleotidi a monte del sito d’inizio. Il legame di TBP nella minor groove induce una marcata curvatura del DNA e una distorsione locale della doppia elica (Figura 03.05-12), creando un punto di riferimento topologico per l’assemblaggio successivo. Oltre alla TATA, subunità TAF di TFIID possono riconoscere elementi core aggiuntivi, quali initiator (Inr), DPE e MTE, spiegando perché alcuni promotori efficaci non possiedano una TATA box canonica.
Dopo l’ancoraggio di TFIID, altri fattori (TFIIA, TFIIB) stabilizzano il legame e dirigono il reclutamento del complesso Pol II–TFIIF, seguito da TFIIE e TFIIH, a costituire il PIC completo. L’ordine di assemblaggio mostrato in (Figura 03.05-11) rappresenta una sequenza possibile, ma variabile a seconda del promotore e del contesto cromatinico. Analogamente ai promotori batterici, anche quelli eucariotici contengono segnali direzionali che determinano quale filamento di DNA venga usato come stampo e la direzione della trascrizione (Figura 03.05-13).
Il passaggio da complesso chiuso a complesso aperto richiede l’attività ATPasica/elicasi di TFIIH, che promuove la fusione locale del DNA al sito d’inizio. Contestualmente, la “coda” C-terminale (CTD) della polimerasi II, formata da ripetizioni eptapeptidiche YSPTSPS, viene fosforilata: la chinasi CDK7 di TFIIH catalizza principalmente la fosforilazione su Ser5, evento chiave per il “promoter escape” e per il reclutamento degli enzimi di capping, come indicato in (Figura 03.05-11). Questo stato fosforilato consente all’enzima di lasciare alle spalle gran parte dei fattori generali e di entrare nella fase di allungamento iniziale.
Una quota dei fattori generali rimane prossima al promotore o si rende rapidamente disponibile per ulteriori cicli di avvio, favorendo la ri-iniziazione. Al termine della trascrizione di un gene, la polimerasi II deve essere ricondotta a uno stato competente per un nuovo innesco: la CTD viene defosforilata da fosfatasi specifiche (ad esempio FCP1 e Ssu72), poiché solo la forma ipodefosforilata della polimerasi II è idonea a rientrare nel ciclo d’inizio.
La configurazione della cromatina modula in modo sostanziale l’efficienza del PIC. Complessi rimodellatori dei nucleosomi (come SWI/SNF e ISWI) e attività enzimatiche che modificano gli istoni (acetiltransferasi e metiltransferasi) cooperano per rendere accessibili i promotori attivi; tipicamente, promotori di geni espressi presentano nucleosomi con segni come H3K4me3 e regioni adiacenti arricchite in H3K27ac. Coattivatori su larga scala, quali il complesso Mediator, integrano i segnali provenienti da enhancer distali e stabilizzano l’interazione con il PIC, contribuendo all’efficiente reclutamento della polimerasi II.
Negli animali, inoltre, è frequente una pausa prossimale al promotore dopo poche decine di nucleotidi trascritti: i complessi NELF e DSIF stabilizzano questa pausa, mentre la chinasi P-TEFb (CDK9) fosforila Ser2 della CTD e componenti del complesso di pausa, facilitando la transizione verso l’allungamento produttivo. Tale modulazione, non mostrata in (Figura 03.05-11), si integra con i passaggi di inizio rappresentati.
Esempio applicativo: in una cellula epatica, un gene per un enzima metabolico può dipendere da un enhancer situato oltre 50 kb a monte. Un fattore “pioneer” apre localmente la cromatina, consentendo l’acetilazione degli istoni e il reclutamento di Mediator. La formazione di un loop cromatinico mette in contatto l’enhancer con il promotore; TFIID si lega agli elementi core (TATA o Inr), TFIIH apre la doppia elica e fosforila la CTD su Ser5, permettendo alla polimerasi II di superare il promotore. La successiva azione di P-TEFb consolida l’allungamento, mentre le fosfatasi CTD, a fine ciclo, ripristinano lo stato compatibile con una nuova iniziazione.
Image Gallery
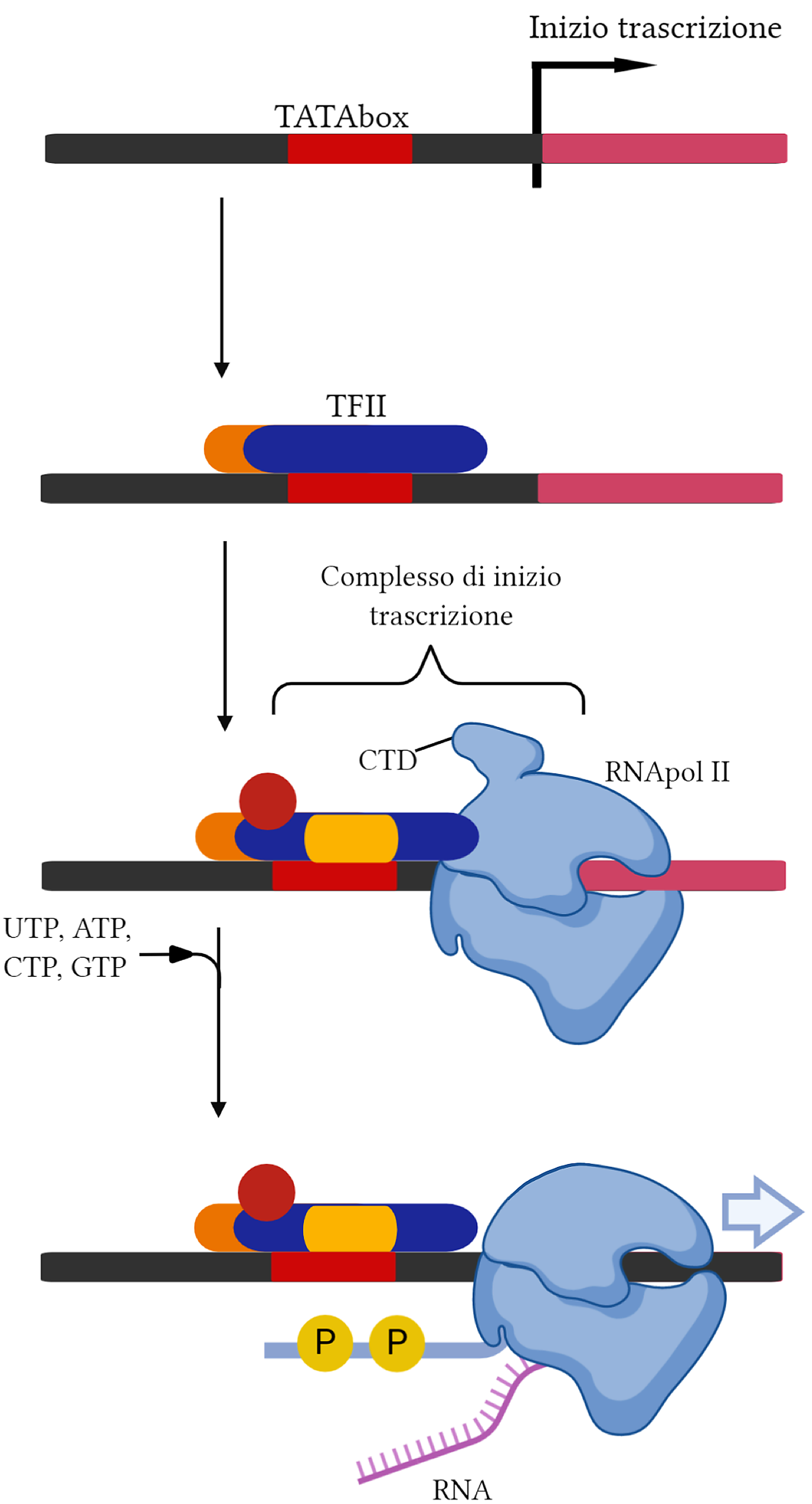
Image Gallery

Image Gallery
Image Gallery
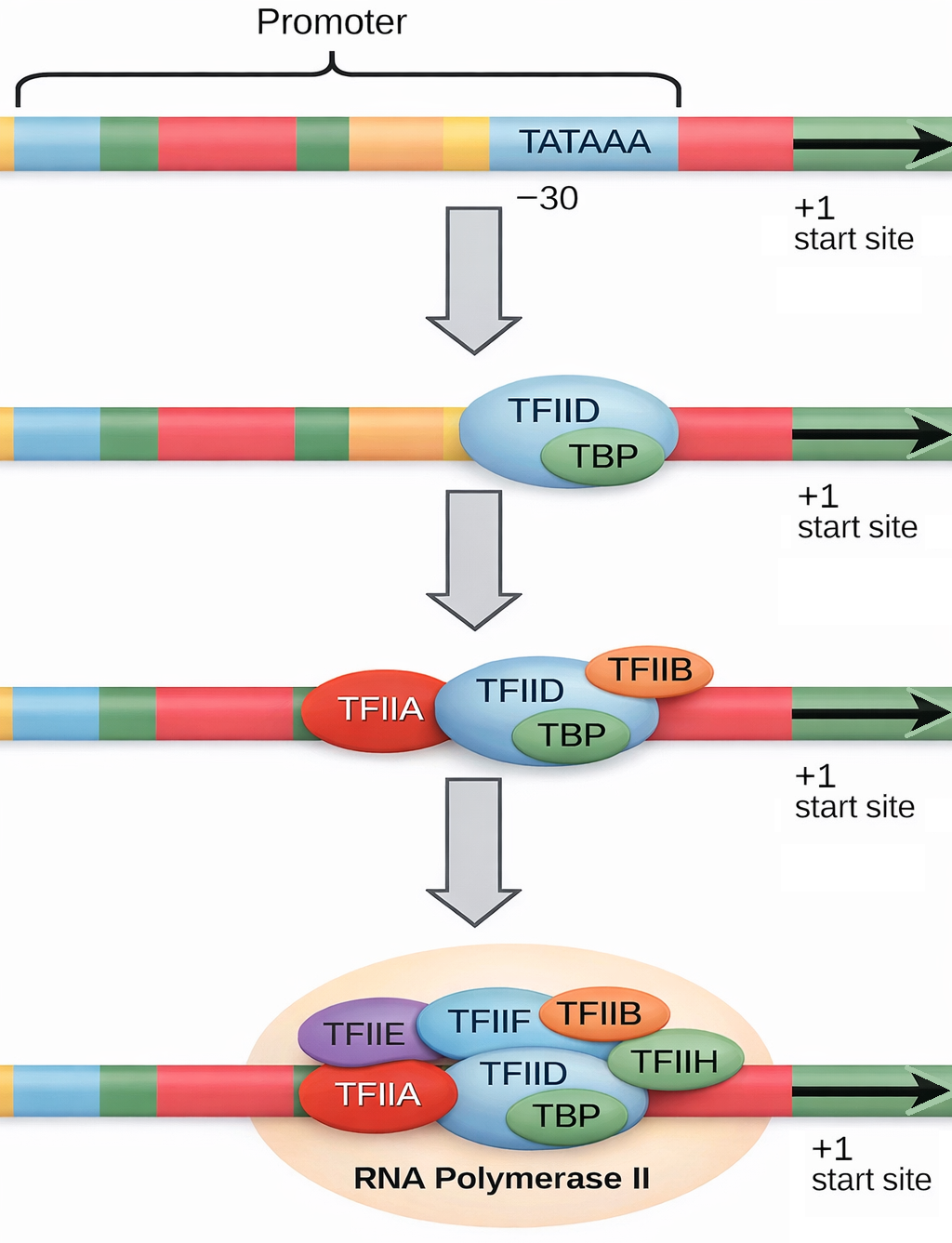
Image Gallery
Image Gallery
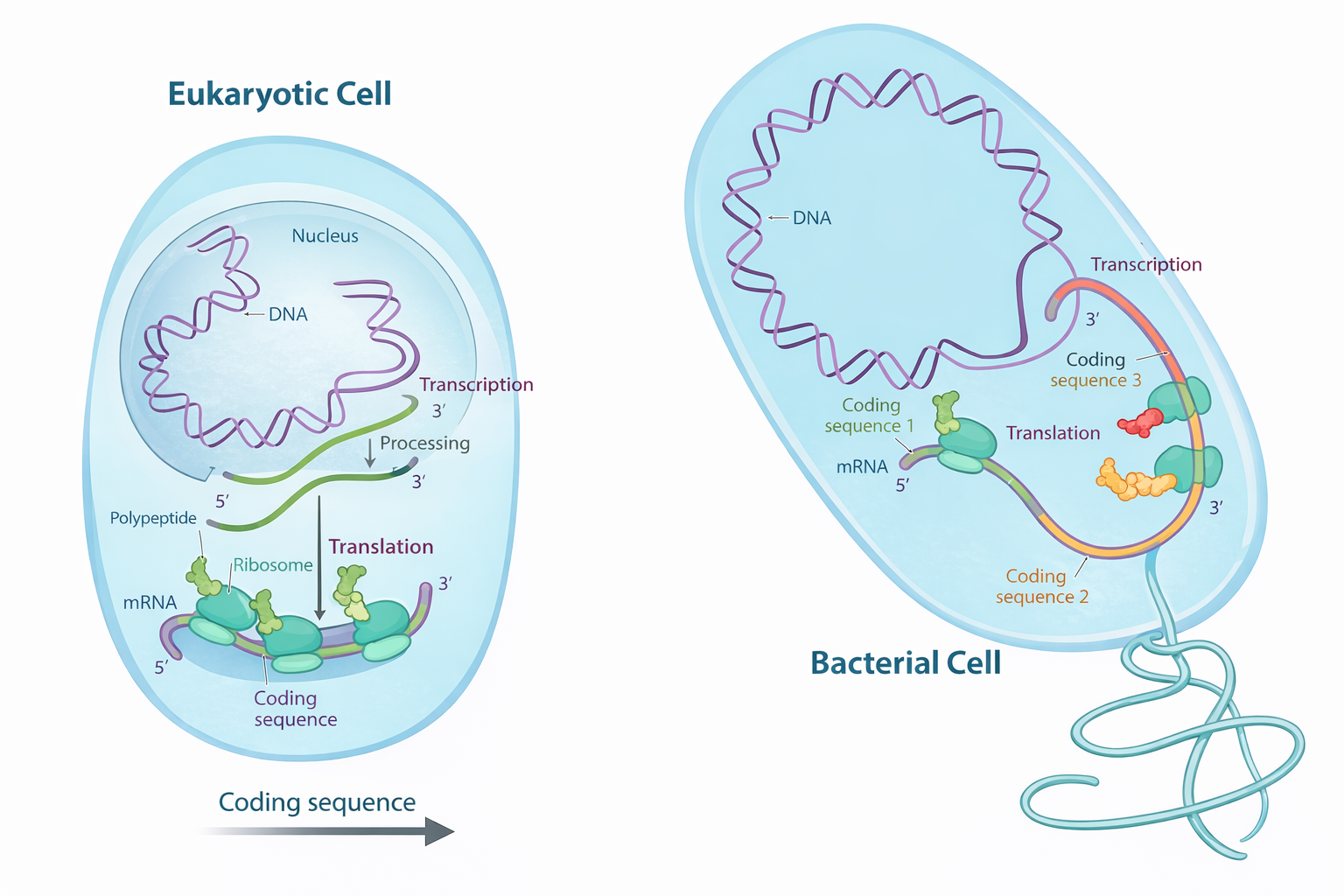
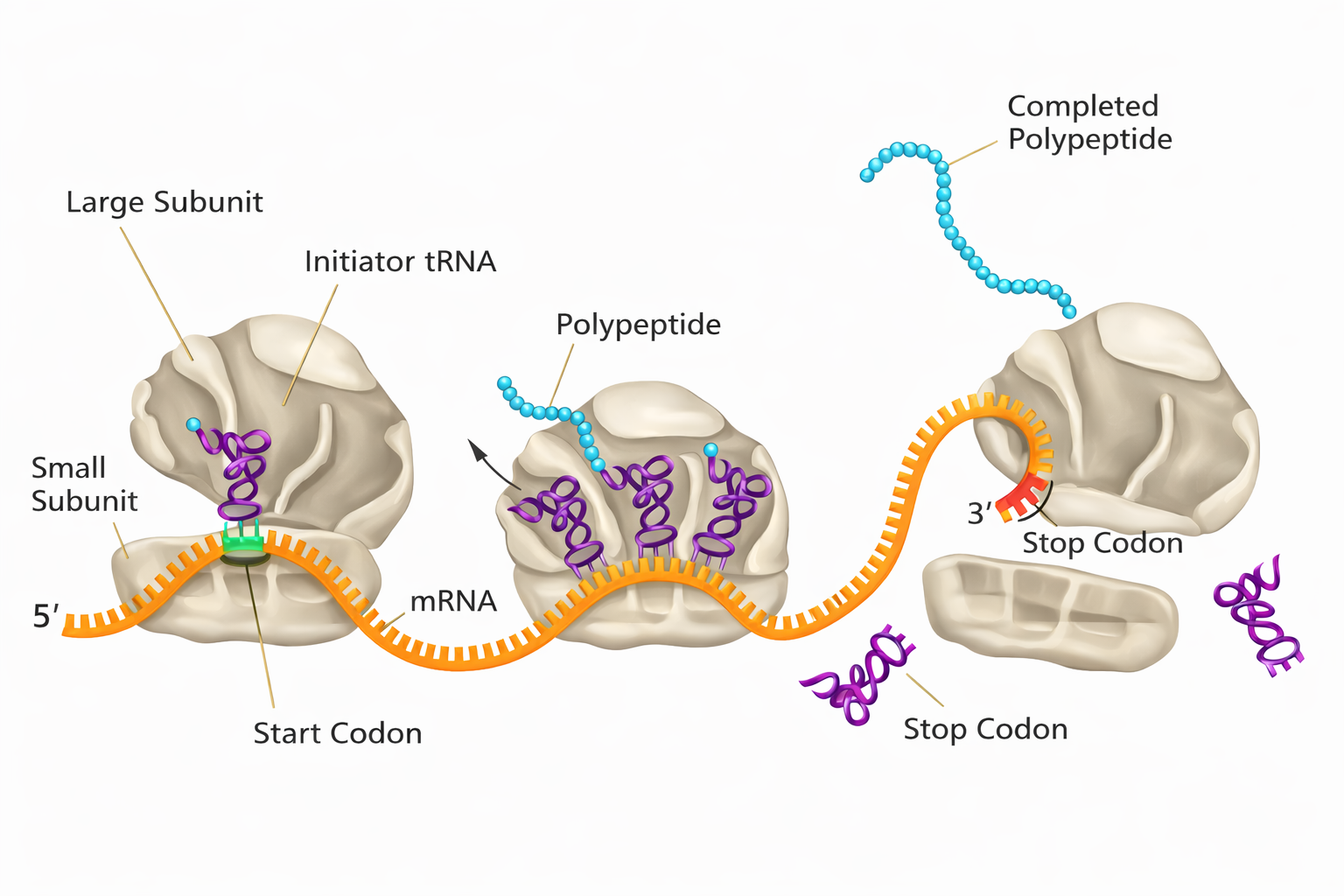
La trascrizione del DNA in RNA è un processo conservato lungo l’evoluzione, ma il destino del trascritto diverge profondamente tra procarioti ed eucarioti. Nelle cellule batteriche, prive di inviluppo nucleare, il genoma è immerso nel citosol, lo stesso compartimento in cui operano i ribosomi; di conseguenza, la traduzione può iniziare mentre l’RNA nasce, con i ribosomi che si associano subito all’estremità 5′ dell’mRNA nascente. Nelle cellule eucariotiche, invece, la trascrizione avviene nel nucleo, mentre la sintesi proteica è eseguita su ribosomi localizzati nel citoplasma; l’mRNA deve quindi essere esportato attraverso i complessi del poro nucleare prima di essere tradotto (Figura 03.05-14). Tale esportazione è strettamente subordinata a un insieme coordinato di modificazioni del trascritto, note come maturazione dell’RNA (RNA processing), che si svolgono per gran parte in modo co-trascrizionale e comprendono capping, splicing e poliadenilazione.
Gli enzimi deputati alla maturazione sono reclutati e organizzati dalla coda carbossi-terminale (CTD) dell’RNA polimerasi II, la quale, grazie a specifiche fosforilazioni dei suoi ripetuti eptapeptidici YSPTSPS, funge da piattaforma dinamica per l’assemblaggio sequenziale dei complessi di processamento (Figura 03.05-11) e (Figura 03.05-15). Due tappe risultano pressoché universali per i trascritti che diventeranno mRNA: l’aggiunta del cappuccio 5′ e la poliadenilazione dell’estremità 3′.
1. Capping 5′. Poco dopo l’inizio della trascrizione, quando il pre-mRNA ha raggiunto circa 20–30 nucleotidi, l’estremità 5′ viene modificata con l’aggiunta di una 7-metilguanosina legata tramite un ponte trifosfato inusuale \(5′\text{–}5′\). Il cappuccio è ulteriormente metilato e riconosciuto dal complesso legante il cappuccio (cap-binding complex, CBC) (Figura 03.05-16). Nei batteri l’estremità 5′ rimane semplicemente trifosforilata e non è cappata.
2. Poliadenilazione 3′. Negli eucarioti, la terminazione dell’mRNA prevede un taglio endonucleolitico del trascritto a valle di una sequenza di segnale di poliadenilazione (tipicamente AAUAAA, con varianti funzionali), seguito dall’aggiunta, ad opera della poli(A) polimerasi, di una coda poliadenilica lunga tipicamente da alcune decine a qualche centinaio di residui (Figura 03.05-16). La coda è rivestita da proteine leganti la poli(A), che ne modulano stabilità ed efficienza traduttiva.
Insieme, cappuccio e poli(A) stabilizzano l’mRNA, ne favoriscono l’esportazione nucleare e fungono da segnali di idoneità per l’avvio della traduzione, assicurando che l’integrità delle estremità 5′ e 3′ sia verificata dagli apparati cellulari.
Image Gallery
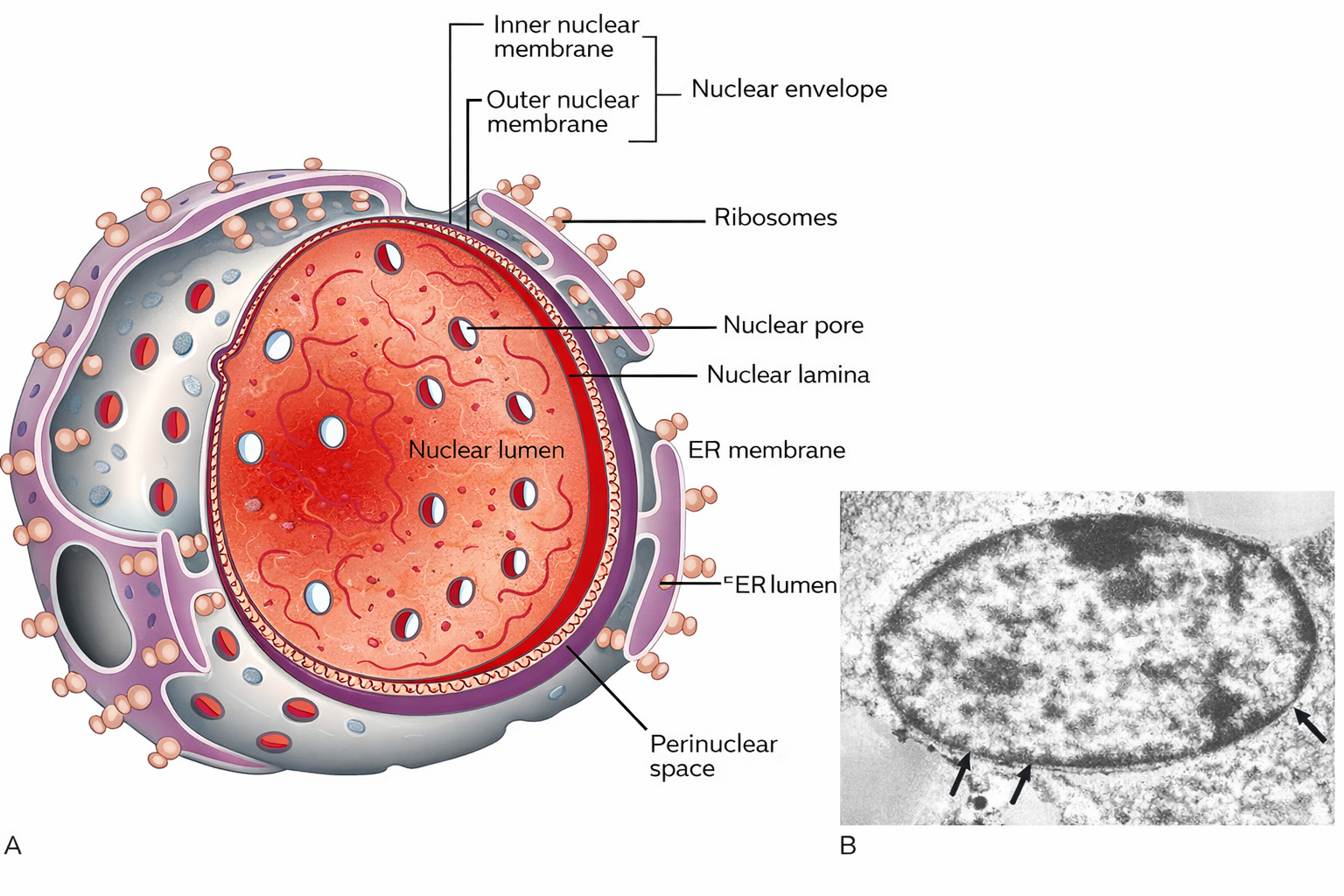
Image Gallery
Image Gallery
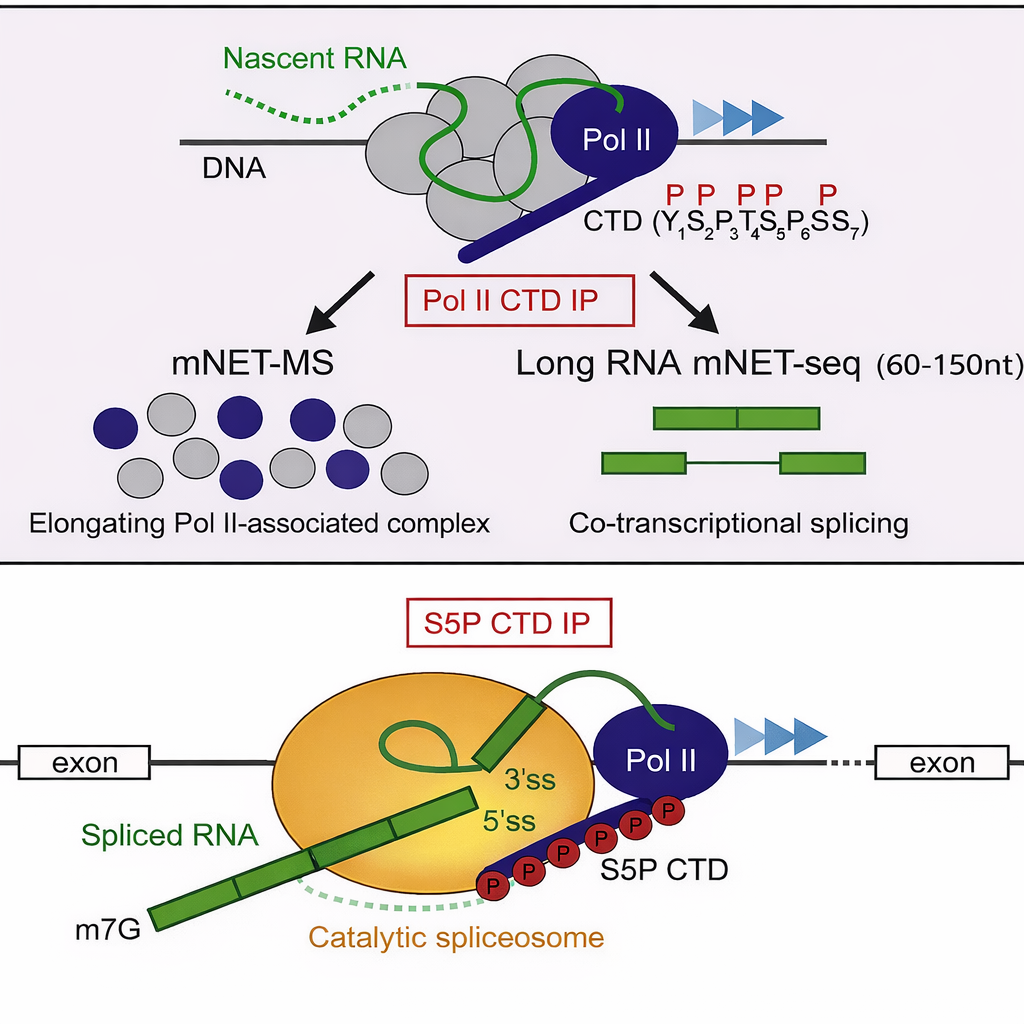
Image Gallery
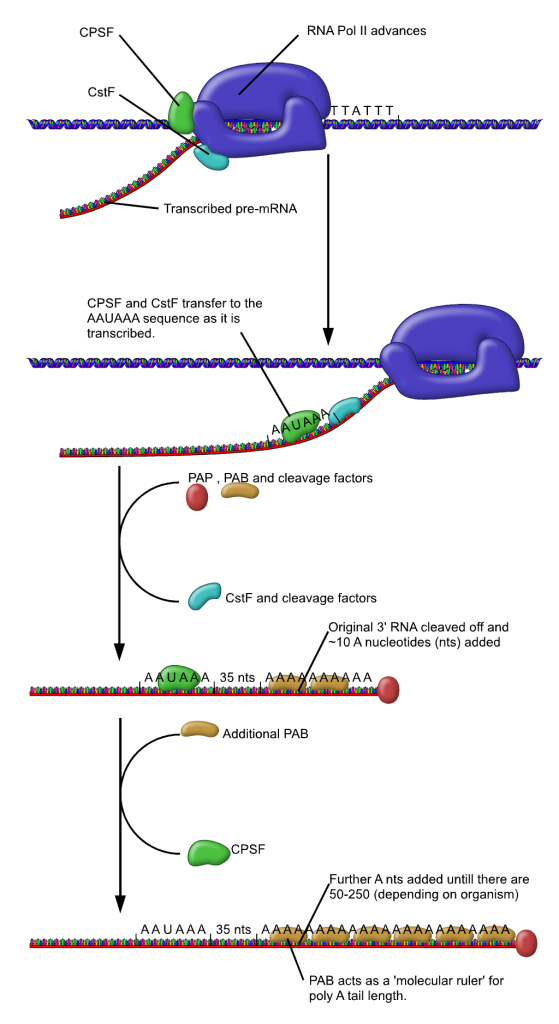
Image Gallery
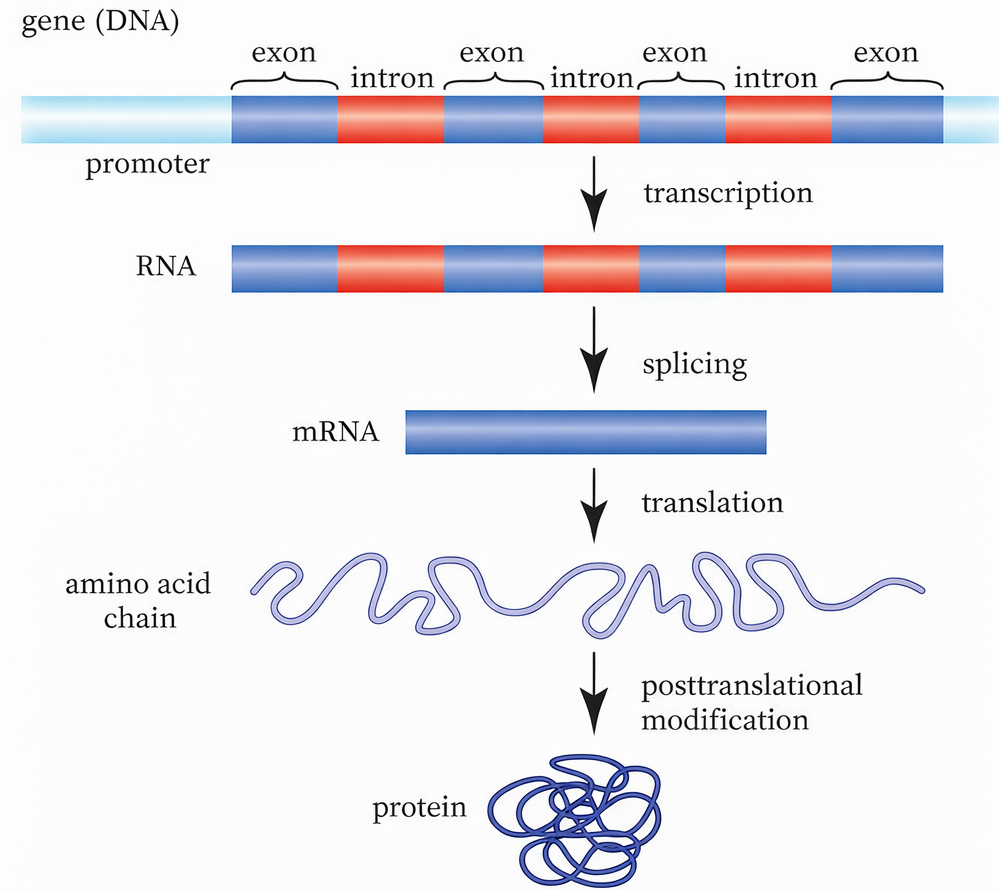
Una peculiarità dei geni eucariotici è la presenza, all’interno delle regioni trascritte, di segmenti non codificanti denominati introni, che interrompono le sequenze codificanti o esoni. Nei procarioti, di norma, l’informazione per una proteina è contenuta in una regione contigua che, una volta trascritta, può essere tradotta senza ulteriori interventi. Negli eucarioti, al contrario, gli esoni sono intervallati da uno o più introni, spesso più lunghi degli esoni stessi, cosicché la porzione effettivamente codificante rappresenta solo una frazione della lunghezza complessiva del gene. La dimensione degli introni è estremamente variabile, da 1 fino a oltre 10 000 nucleotidi, e la loro numerosità per gene differisce tra loci e specie: alcuni geni sono intron-less, altri contengono pochi introni, molti ne possiedono numerosi (Figura 03.05-01). Le denominazioni “esone” e “introne” si applicano tanto al DNA quanto agli RNA corrispondenti trascritti da tali regioni.
Image Gallery
Il trascritto primario prodotto dall’RNA polimerasi II (pre-mRNA) include sia esoni sia introni. Dopo il capping, e mentre la trascrizione procede, si attiva lo splicing, processo di taglio e giunzione che elimina gli introni e ricuce gli esoni in continuità. La poliadenilazione del 3′ avviene al termine o, in molti casi, in parallelo alle reazioni di splicing. Il risultato finale, un mRNA con cappuccio 5′, giunzioni esone–esone e coda poli(A), è competente per l’export e la traduzione.
La cellula identifica gli introni grazie a brevi segnali cis conservati, posizionati alle estremità introniche e in prossimità del punto di ramificazione: un dinucleotide quasi invariante GU al 5′, un AG al 3′, una sequenza di ramificazione contenente una adenina reattiva e, spesso, un tratto polipirimidinico a valle del branch point. Lo splicing procede mediante due transesterificazioni che generano un “lariat”, un cappio intronico, in cui l’adenosina del branch point forma un insolito legame \(2′\text{–}5′\) con il primo nucleotide dell’introne (Figura 03.05-17).
Queste reazioni sono catalizzate in gran parte da RNA, non da proteine. Piccoli RNA nucleari (snRNA) — tra cui U1, U2, U4, U5 e U6 — assemblati con proteine formano le particelle snRNP, che riconoscono per appaiamento di basi i segnali di splicing sul pre-mRNA, orchestrano i riarrangiamenti conformazionali e promuovono la catalisi; gli RNA catalitici coinvolti rientrano nella categoria dei ribozimi (Figura 03.05-18). Le snRNP e numerose proteine accessorie costituiscono lo spliceosoma, un grande complesso dinamico responsabile della rimozione degli introni e della giunzione esonica.
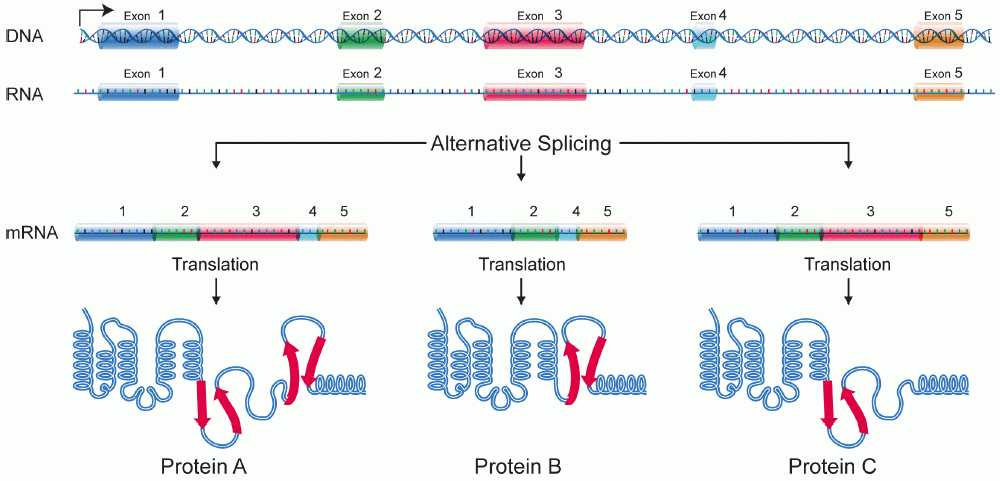
L’organizzazione intron–esone, apparentemente onerosa, conferisce vantaggi sostanziali. Lo splicing alternativo consente di generare più isoforme proteiche dallo stesso gene mediante combinazioni differenziali di esoni: salti di esoni, esoni mutuamente esclusivi, siti di splicing 5′/3′ alternativi, ritenzione intronica (Figura 03.05-19). Nell’uomo, una larga maggioranza dei geni subisce splicing alternativo. La scelta dei siti è modulata da elementi regolatori in cis (enhancer/silencer esonici e intronici) e da proteine regolatrici (ad esempio SR e hnRNP), ampliando enormemente la capacità informativa del genoma.
Image Gallery
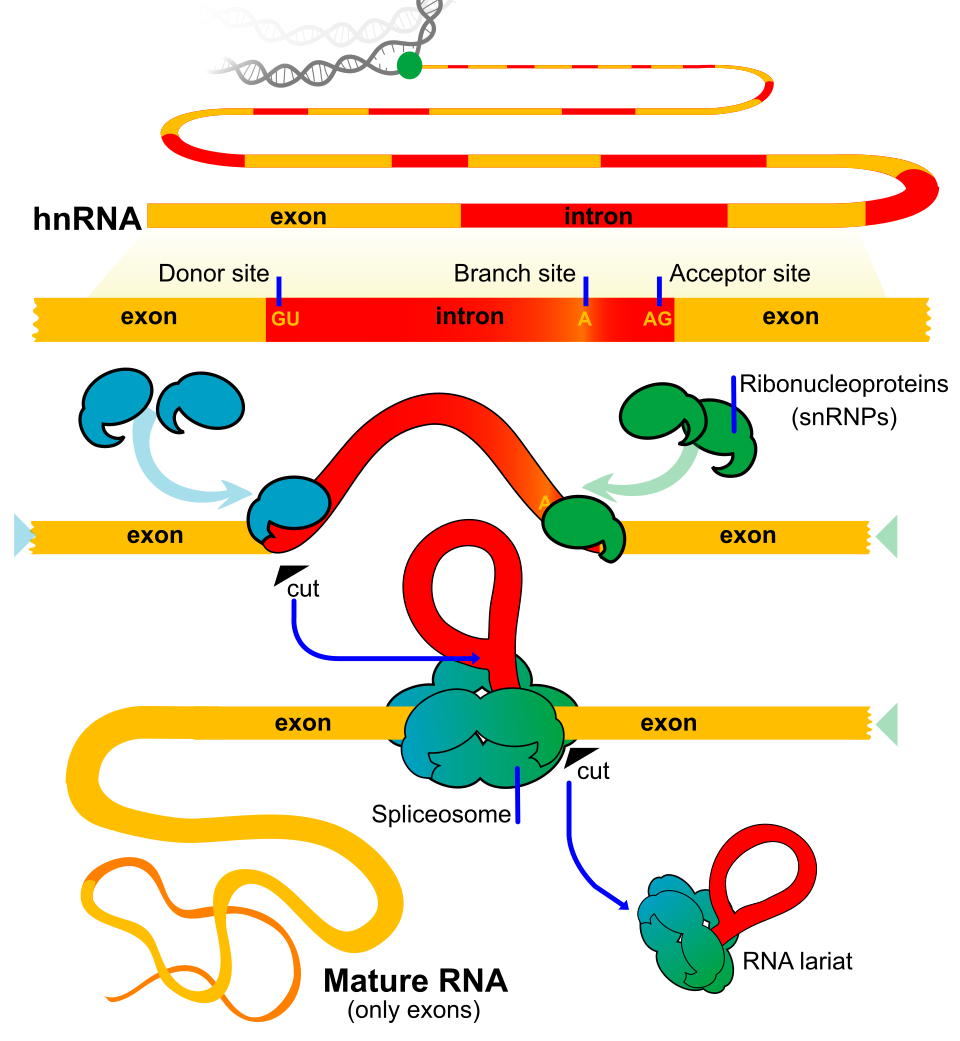
Image Gallery
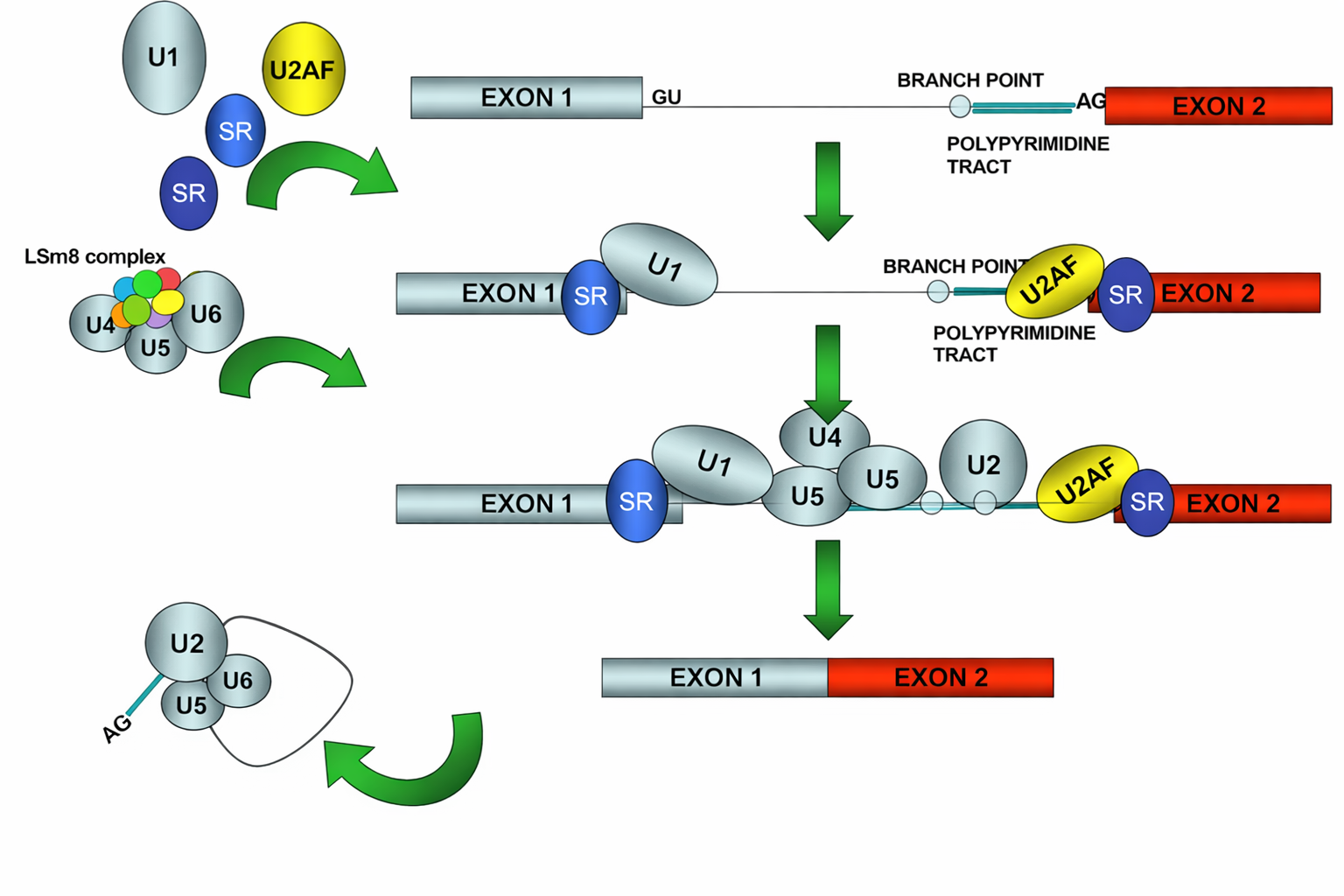
Image Gallery
La produzione coordinata degli RNA eucariotici implica la collaborazione di RNA polimerasi, fattori di trascrizione e macchinari di processamento per capping, poliadenilazione e splicing. Oltre al reclutamento co-trascrizionale sulla CTD dell’RNA polimerasi II (Figura 03.05-15), questi componenti si organizzano in condensati biomolecolari privi di membrana — spesso generati per separazione di fase — che agiscono come “fabbriche” funzionali, visibili al microscopio come domini nucleari specializzati (Figura 03.05-07). In tali microambienti si concentrano enzimi e substrati, incrementando efficienza e fedeltà delle reazioni.
Organizzazioni analoghe interessano altri processi: la replicazione e la riparazione del DNA avvengono in “fabbriche” dedicate; i geni dell’rRNA si raggruppano nel nucleolo, dove l’rRNA si associa a proteine per costituire le subunità ribosomiali (Figura 03.05-16). Nel nucleo sono inoltre osservabili corpi di Cajal e “nuclear speckles”, coinvolti rispettivamente nella biogenesi di snRNP e nello stoccaggio di fattori di splicing. I ribosomi maturi e gli mRNA completamente processati sono poi esportati nel citoplasma per la traduzione.
Image Gallery
Image Gallery
Image Gallery
Solo una frazione dei trascritti prodotti diventa mRNA maturo; la restante comprende introni escissi, trascritti parziali o RNA mal assemblati che devono essere trattenuti e degradati nel nucleo. L’uscita verso il citoplasma è dunque selettiva e dipende dal riconoscimento, da parte del complesso del poro nucleare, di mRNA correttamente processati e marcati da specifiche proteine (Figura 03.05-14). Tra i segnali di idoneità figurano:
- il complesso legante il cappuccio sul 5′ (CBC), che tutela l’estremità e coordina l’assemblaggio di ulteriori fattori;
- le proteine leganti la poli(A) nucleari sul 3′, che segnalano una corretta poliadenilazione;
- il complesso di giunzione esonica (exon junction complex, EJC), depositato a valle dei siti di splicing e indicativo di giunzioni esone–esone formate correttamente;
- il complesso TREX e i recettori di esportazione NXF1/TAP e NXT1/p15, che mediano l’interazione con il poro nucleare e il passaggio nel citoplasma;
- i sistemi di sorveglianza nucleare, inclusa l’esosoma, che riconoscono e degradano RNA difettosi, prevenendone l’uscita.
È la combinazione di questi marcatori a determinare l’“autorizzazione” all’export. Gli RNA non idonei restano confinati e sono riciclati, preservando l’accuratezza dell’espressione genica.
Image Gallery
Una volta nel citoplasma, un mRNA può essere tradotto ripetutamente prima di essere eliminato; per questo, la sua emivita contribuisce in modo sostanziale all’abbondanza proteica (Figura 03.05-01). Le RNasi citoplasmatiche degradano gli mRNA seguendo percorsi regolati, e le velocità di decadimento variano ampiamente in base alla sequenza dell’mRNA e al contesto cellulare. Nei batteri, gli mRNA sono generalmente effimeri e spesso mostrano emivite di pochi minuti (ad esempio 2,5–5,0 minuti), favorendo risposte rapide. Negli eucarioti, la longevità è più eterogenea: alcuni messaggeri hanno emivite inferiori a 20 minuti, altri superano diverse ore; per esempio, l’mRNA dell’albumina epatica è relativamente stabile, mentre quello di fattori di risposta immediata, come c-FOS, è rapidamente degradato. Elementi regolatori nelle regioni non tradotte, in particolare nella 3′ UTR situata tra il codone di stop e la coda poli(A) (Figura 03.05-16), modulano stabilità e traducibilità. Sequenze ricche in AU (ARE), siti di legame per microRNA e strutture secondarie possono reclutare fattori che accelerano o rallentano il decadimento. I principali percorsi includono:
- deadenilazione dipendente da complessi come CCR4–NOT o PAN2–PAN3, seguita da decapping operato da DCP2/DCP1 e degradazione 5′→3′ tramite XRN1;
- degradazione 3′→5′ mediata dall’esosoma citoplasmatico dopo accorciamento della poli(A);
- tagli endonucleolitici specifici (ad esempio in risposta a microRNA o durante il nonsense-mediated decay, NMD, che elimina trascritti con codoni di stop prematuri marcati dagli EJC);
- sequestro e rimodellamento in corpi citoplasmatici come P-bodies e stress granules, che fungono da hub per repressione traduttiva e turnover.
In generale, proteine necessarie in grandi quantità o in modo costitutivo tendono a derivare da mRNA più stabili, mentre funzioni regolative o di risposta rapida si appoggiano a mRNA a vita breve. Una sintesi comparativa di trascrizione, maturazione ed eliminazione degli RNA in procarioti ed eucarioti è illustrata nella (Figura 03.05-20).
Image Gallery
Image Gallery
Image Gallery