I carboidrati servono da combustibili e come materiali da costruzione
Definizione

Prima di chiarire l’organizzazione intima dell’acido desossiribonucleico, i biologi avevano già messo in relazione l’ereditarietà con i cromosomi. Queste strutture, così denominate per la loro affinità alle colorazioni istologiche (dal greco chroma, “colore”), furono individuate nell’Ottocento come elementi filamentosi visibili nel nucleo all’avvio della divisione cellulare (Figura 02.02-01). L’analisi chimica condotta in seguito rivelò che i cromosomi sono costituiti da DNA e proteine. Rimaneva però controverso quale dei due componenti fosse il supporto dell’informazione genetica.
È oggi accertato che il DNA veicola l’informazione ereditaria e che le proteine cromosomiche, in larga parte istoni e fattori accessori, forniscono l’impalcatura per compattare e modulare l’attività delle lunghe molecole di DNA. Nonostante ciò, fino agli anni ’40 del Novecento appariva controintuitivo che una molecola apparentemente semplice, composta da ripetizioni di soli quattro tipi di subunità, potesse codificare l’enorme varietà dei tratti biologici.
Nei primi anni ’50, le immagini di diffrazione a raggi X ottenute da Maurice Wilkins e Rosalind Franklin fornirono indizi decisivi sull’assetto tridimensionale del DNA. Tali evidenze confluirono nel 1953 nel modello a doppia elica proposto da James Watson e Francis Crick, nel quale due filamenti si avvolgono l’uno sull’altro formando un’elica stabile e regolare. La struttura suggeriva già come il DNA potesse immagazzinare istruzioni biologiche e, soprattutto, come esse potessero essere copiate e trasmesse durante la divisione cellulare. Di seguito vengono analizzati i tratti strutturali che rendono il DNA un supporto efficiente e fedele dell’informazione ereditaria.
Image Gallery
L’acido desossiribonucleico è costituito da due lunghe catene polinucleotidiche (filamenti) mantenute insieme da interazioni specifiche tra basi azotate (Figura 02.02-02). Ogni nucleotide comprende tre componenti: uno zucchero a cinque atomi di carbonio (desossiribosio), un gruppo fosfato e una base azotata. Le basi del DNA sono quattro, suddivise in purine e pirimidine: adenina (A) e guanina (G) sono purine a doppio anello, citosina (C) e timina (T) sono pirimidine a singolo anello.
I nucleotidi si uniscono in catena tramite legami fosfodiesterici che coinvolgono il gruppo fosfato al carbonio 5′ di un nucleotide e il gruppo ossidrile al carbonio 3′ del successivo, generando una “ossatura” zucchero-fosfato ripetitiva (Figura 02.02-02); (Figura 02.02-03). Questa modalità di connessione conferisce a ogni filamento una polarità chimica definita, con estremità distinguibili: l’estremità 5′, che espone di norma un fosfato, e l’estremità 3′, recante un gruppo ossidrile libero. La carica negativa dei fosfati contribuisce alla solubilità del DNA in ambiente acquoso e alle sue interazioni con proteine basiche.
Le basi sporgono dall’ossatura verso l’interno della molecola a doppia elica e formano coppie specifiche mediante legami idrogeno: A si appaia con T, e G con C (Figura 02.02-04). La complementarità purina–pirimidina garantisce che tutte le coppie abbiano ingombro simile, mantenendo costante la distanza tra le ossature zucchero-fosfato (Figura 02.02-02). Le coppie G≡C formano in media tre legami a idrogeno e le coppie A=T due, ma la stabilità della doppia elica dipende in maniera rilevante anche dalle interazioni di impilamento tra basi adiacenti, che minimizzano l’esposizione di superfici idrofobiche e stabilizzano l’elica.
I due filamenti del DNA decorrono in direzioni opposte, cioè sono antiparalleli: la polarità 5′→3′ di un filamento è opposta a quella del filamento complementare (Figura 02.02-02). In condizioni fisiologiche, i filamenti si avvolgono nella forma B del DNA, caratterizzata da circa 10,5 coppie di basi per giro, un passo elicoidale di ~3,4 nm e una distanza media di ~0,34 nm tra coppie di basi successive (Figura 02.02-05). La geometria della doppia elica determina anche due solchi di accesso, maggiore e minore, che fungono da superfici di riconoscimento per proteine regolatorie e complessi enzimatici.
La regola di appaiamento complementare (Figura 02.02-04) implica che la sequenza di un filamento determini univocamente quella dell’altro: ad ogni A corrisponde una T, e ad ogni C una G. Questa proprietà è alla base sia della copiatura accurata del DNA sia dei meccanismi di riparazione che riconoscono e correggono appaiamenti errati.
Alcuni elementi strutturali aggiuntivi raffinano il quadro generale:
- forme alternative: oltre alla forma B, il DNA può adottare conformazioni A (più compatta, favorita in condizioni di minore idratazione) e Z (elica sinistrorsa ricca in sequenze GC), con implicazioni funzionali locali;
- composizione in basi e stabilità: una maggiore frazione di G+C tende ad aumentare la temperatura di fusione \( T_m \); per brevi duplex si usa spesso l’approssimazione \( T_m \approx 2^\circ\text{C}\times(N_{A+T}) + 4^\circ\text{C}\times(N_{G+C}) \);
- distinzione da RNA: l’assenza del gruppo 2′-OH nel desossiribosio e la presenza di timina (al posto dell’uracile) rendono il DNA chimicamente più stabile, particolarmente rilevante per l’archiviazione a lungo termine dell’informazione genetica.
Image Gallery

Image Gallery
Image Gallery

Image Gallery

Image Gallery
Image Gallery
Image Gallery

Image Gallery
I geni sono segmenti di DNA che conservano istruzioni biologiche e devono essere duplicati e trasferiti con alta fedeltà durante la divisione cellulare. Il problema biologico è duplice: come codificare l’informazione in forma molecolare e come replicarla con precisione. La doppia elica del DNA risponde a entrambe le esigenze.
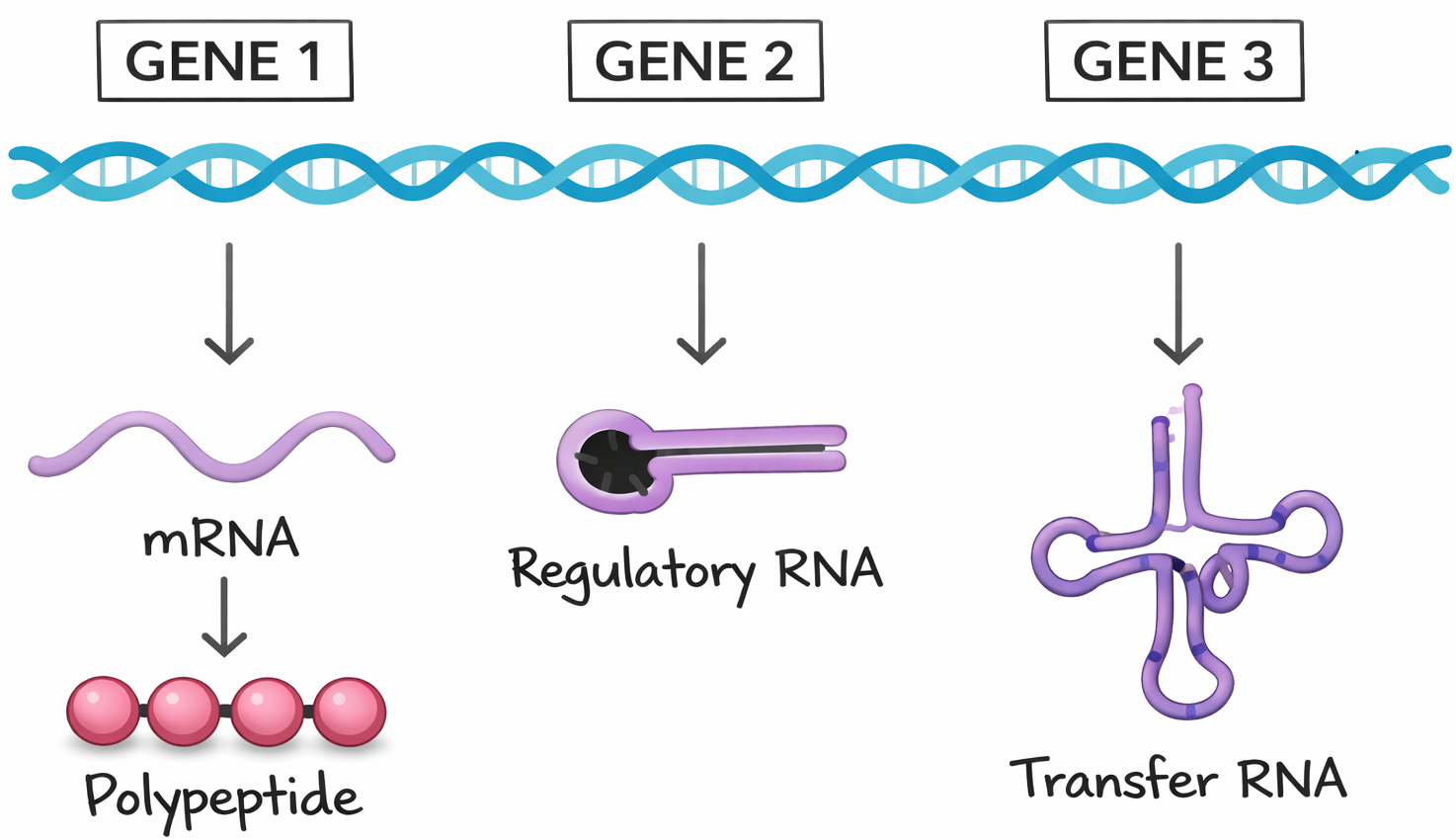
L’informazione è rappresentata dall’ordine delle basi lungo ciascun filamento. La sequenza nucleotidica può essere vista come un testo scritto con un alfabeto di quattro simboli (A, C, G, T) che, in combinazioni diverse, specifica funzioni e tratti distintivi degli organismi (Figura 02.02-06). Differenze tra specie o tra individui derivano, in ultima analisi, da variazioni nella sequenza del DNA che alterano i messaggi genetici.
Già prima della definizione della doppia elica era stato riconosciuto che i geni forniscono le istruzioni per sintetizzare proteine. Poiché l’attività di una proteina dipende dalla sua conformazione tridimensionale, determinata dalla sequenza degli amminoacidi, ne discende che la sequenza lineare dei nucleotidi in un gene deve essere convertita nella sequenza lineare degli amminoacidi nella proteina. Questa conversione avviene tramite l’espressione genica: la cellula trascrive il tratto di DNA in RNA e poi traduce l’informazione dell’RNA in una catena polipeptidica seguendo il codice genetico, una corrispondenza ben definita tra triplette nucleotidiche e amminoacidi (Figura 02.02-07).
La struttura a doppia elica fornisce anche la soluzione al problema della copiatura. Durante la replicazione, i due filamenti si separano e ciascuno funge da stampo per la sintesi del filamento complementare, secondo un principio semiconservativo che preserva l’informazione base per base grazie alla complementarità A–T e G–C. La direzionalità 5′→3′ della polimerizzazione nucleotidica e i sistemi di correzione delle bozze e di riparazione degli errori contribuiscono a mantenere bassi i tassi di mutazione, senza impedire l’insorgenza di variazioni utili all’evoluzione.
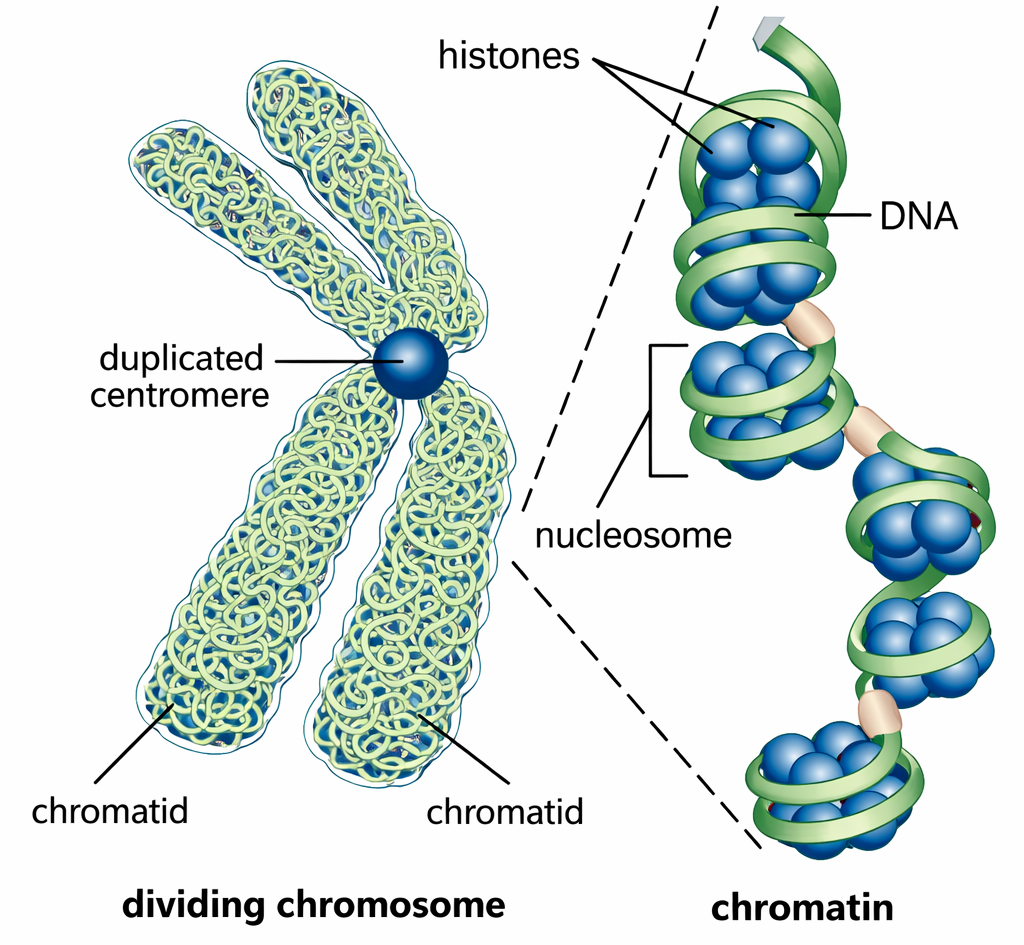
La quantità di informazione codificata nel DNA è enorme: la sequenza completa di un gene umano di dimensioni modeste può occupare poche righe se scritta con l’alfabeto a quattro lettere, mentre l’intero genoma umano, pari a circa 3,2 miliardi di coppie di basi, richiederebbe un numero molto elevato di volumi per essere riportato integralmente. Ne deriva una sfida architetturale cruciale per i cromosomi eucariotici: come condensare un polimero così lungo nello spazio ristretto del nucleo, assicurando al contempo accesso selettivo all’informazione per replicazione, riparazione ed espressione.
Image Gallery
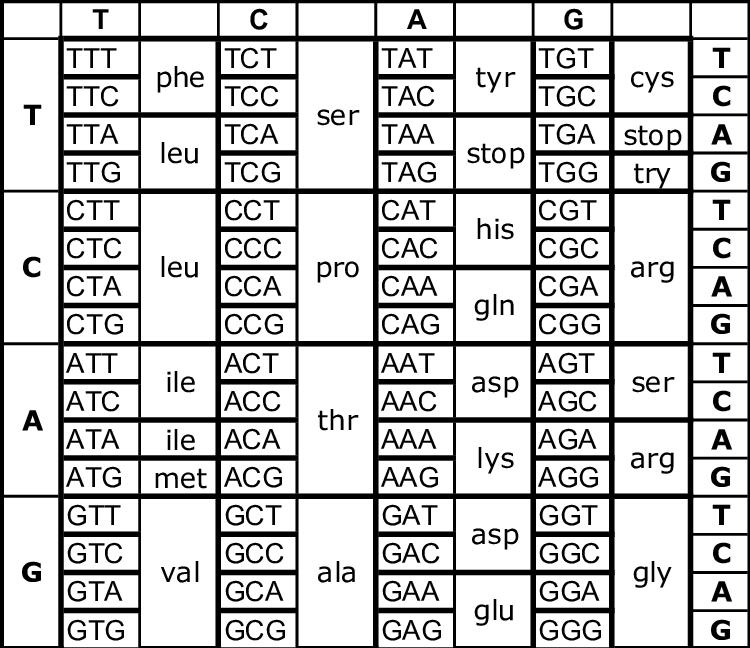
Image Gallery